Multimodal AI | What Is It & Its Major Use Cases Across Different Industries
Artificial Intelligence
 Vishnu Narayan
November 10, 2023
Vishnu Narayan
November 10, 2023


 Vishnu Narayan
November 10, 2023
Vishnu Narayan
November 10, 2023
For anyone curious about the next frontier of AI models, the spotlight is on ‘Multimodal AI’ systems. Thinking why?
Well, right now, AI is like an intelligent friend—it can chat with you and answer almost all of your queries on the go.
However, the future AI will be more advanced. It will be your all-in-one companion!
It won’t just chat; it’ll show you images, play tunes, and get creative with videos, and it can do much more.
It’s like going from a black-and-white TV to a 4K experience!
Therefore, this new AI will be a game-changer, making conversations not just words but a dynamic mix of everything your senses can soak in.
Rather than a vague concept, it’s a straightforward upgrade to make AIs smarter and more versatile. How does that sound?
Read on and stick to the end to learn more interesting facts about Multimodal AI and its amazing use cases across various industries.
Multimodal AI is like a super-smart assistant that can handle different kinds of information—words, pictures, and even spoken words.
Moreover, It’s trained by showing many examples where, say, a picture is paired with a description.

So, when you give it a new picture, it doesn’t just see shapes and colors. Rather, it understands what’s going on and can even tell you about it in words.
Similarly, if you tell it something, it can create a mental picture.
Multimodal AI works through a process of training and learning, and it involves exposing the AI model to datasets that contain examples from different modalities, such as paired images and text descriptions.
In addition, the training process teaches the model to recognize patterns and associations between different data types.
To put it simply, think of it like teaching a computer to understand both pictures and words by showing it lots of examples.
 It learns to connect what it sees in a picture with the words that describe it.
It learns to connect what it sees in a picture with the words that describe it.
After this training, you can give it a new picture, and it will tell you what’s in it, or give it some words, and it’ll create a matching picture.
See, doesn’t it look like a high-tech language and image understanding combo? That’s Multimodal AI for you!
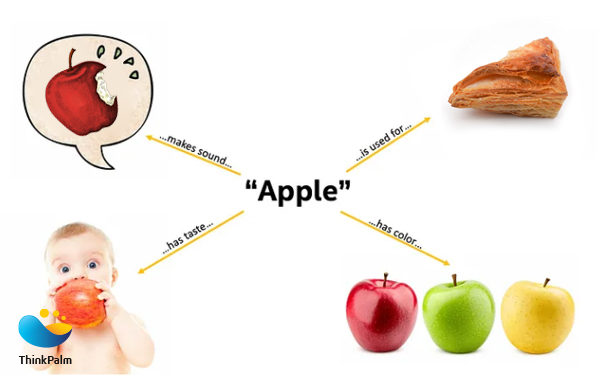
Human brains are awesome at learning from different things. Take the example of an apple.
It’s not just about how it looks; it’s also about the sound it makes when you bite into it, the cultural references like apple pie, and all the detailed info you find in books or online.
Humans grasp the concept of an apple using various sources.
A smart AI system can learn from lots of places—pictures, text, you name it. And guess what? It can use all that learning to solve any kind of problem.
So, if it learned something from a picture or a database, it can use that info to answer a question in regular language.
Similarly, if it learned from text, it can apply that knowledge when dealing with pictures.
It’s like everything connects through these big ideas that work across all kinds of learning—just like saying, “A dog is always a dog,” no matter how you look at it!
And when it comes to common sense, humans have much of it. We know birds fly and cars drive on the road, and we pick up this common sense from what we see, hear, and feel.
But AI often lacks this common sense. That’s where multimodal systems come in. They provide a way to teach AI common sense by letting it learn from different sources—like images, text, and sounds.
For instance, if you show AI a picture of a car and read about its wheels, the AI needs to connect the idea of wheels in both the image and the text.
It’s like making the AI understand that the picture and the words are discussing the same thing. That’s how we make AI really smart!
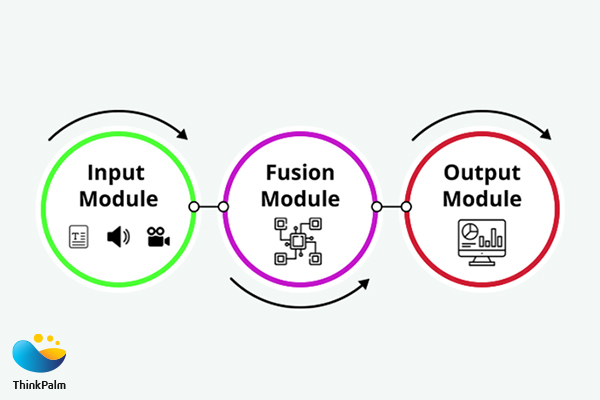
Typically, multimodal AI architecture consists of three key components: input module, fusion module, and output module.
Unimodal AI focuses on processing and understanding information from a single source or modality, such as text, images, or speech.
For example, a system that only analyzes text would be considered unimodal.
On the other hand, multimodal AI deals with multiple modalities simultaneously.
Moreover, it can process and understand information from various sources like text, images, and speech, combining insights from different modalities to enhance overall comprehension.
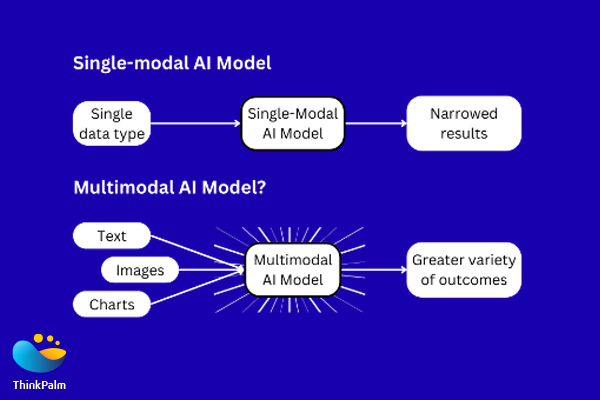
This can lead to a more robust and nuanced understanding than unimodal systems.
In a nutshell, unimodal AI specializes in one type of data, while multimodal AI integrates and interprets information from different sources.
There are numerous advantages of multimodal AI, which include:
Here are a few practical examples of Multimodal AI in action:


Basically, Multimodal AI is your upgraded, versatile AI companion that understands and works with all kinds of information, and its applications are endless.
Multimodal AI’s versatility makes it a game-changer across various industries, and it makes the future of Multimodal AI quite promising.
Read Also: How Artificial Intelligence & Machine Learning are Revolutionizing the OTT Industry
What Is Multimodal Artificial Intelligence?
Multimodal AI is a fresh approach to artificial intelligence that blends different types of data—such as images, text, speech, and numerical information—using multiple intelligent processing algorithms. This fusion often results in superior performance compared to AI systems that focus on a single type of data in various real-world challenges.
What Is Multimodal And An Example?
Multimodal texts integrate different modes, including written and spoken language, visual elements (still and moving images), audio, gestures, and spatial meaning.
What Are The 4 Types Of Multimodality?
Multimodal learning involves four main methods: visual, auditory, reading/writing, and kinesthetic (VARK). While some experts suggest people may favor one, like visual learning, there’s not much solid evidence supporting these preferences.
What Are The Challenges Of Multimodal AI?
Multimodal AI faces five key challenges: representation, translation, alignment, fusion, and co-learning.
In a nutshell, Multimodal AI is changing the AI game, bringing together data from different sources for a smarter and more connected world.
OpenAI, the brain behind ChatGPT, joined the Multimodal AI game on September 25, adding image analysis and speech synthesis for mobile apps.
Why the rush? Google’s Gemini was already making waves in testing. Moreover, as AI giants race to the top, they’re reshaping how we interact with technology.
On the other hand, Google’s chatbot, Bard, has also been rocking multimodality since July 2023.
Now, ChatGPT, joining the crew in October, does more than just understand text—it reads, visualizes, chats, and even recognizes images.
Businesses, a golden opportunity awaits you to embark on a revolutionary journey!
Dive into the endless possibilities of multimodal AI to surf the wave of innovation.
Connect with our AI experts and unlock the potential of state-of-the-art AI Development Services today.
Vishnu Narayan is a dedicated content writer and a skilled copywriter working at ThinkPalm Technologies. More than a passionate writer, he is a tech enthusiast and an avid reader who seamlessly blends creativity with technical expertise. A wanderer at heart, he tries to roam the world with a heart that longs to watch more sunsets than Netflix!