Will GraphQL Overtake REST APIs to Become The Next Big Thing in Application Programming Interface?
Application Development
 Lijo M Loyid
March 31, 2021
Lijo M Loyid
March 31, 2021


 Lijo M Loyid
March 31, 2021
Lijo M Loyid
March 31, 2021
GraphQL has gained a lot of popularity in recent years and is a great alternative to REST. GraphQL is simply a query language for API. It gives us the freedom to ask for exactly what we need and helps us get the required response. Due to the fact that application development with GraphQL controls the size of data response they get back, it is must faster and stable.
Facebook started GraphQL as an internal project in 2012 to overcome data fetching issues of their application. Facebook made GraphQL open source in 2015. Today there are a huge number of libraries and tools that have been developed to support the GraphQL ecosystem across various programming languages.
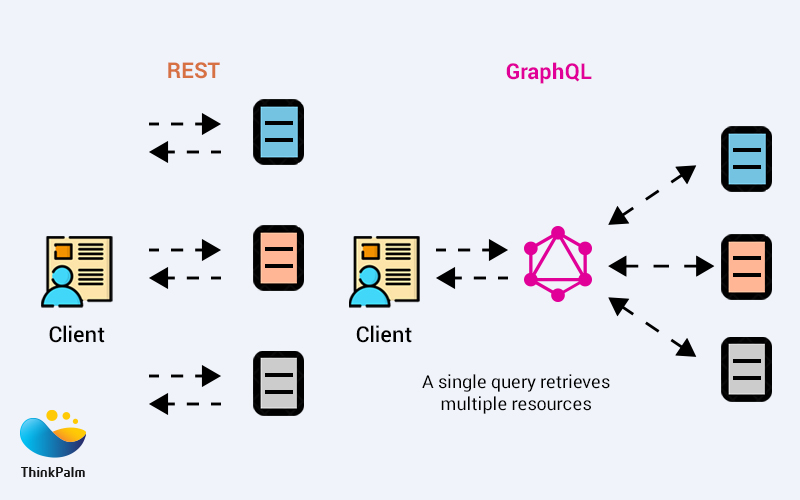
GraphQL is basically a query language for the API. It has been developed as an efficient alternative to REST. With regular REST APIs, we hit an API endpoint from the client and the API returns a JSON object with a lot of other data in response. Instead of hitting a URL endpoint and getting a large JSON object back, in GraphQL, we write a query to request exactly the data that we want.

Here is a request for just the name of the ship and country. The client doesn’t want any other information, even if it’s available. Here, the client is passing an argument to request the information of only two ships. The response that is received is a JSON object that is similar to the request.

With GraphQL we can get all the data that we need within a single request. GraphQL allows us to group queries and fetches all the data in a single request, avoiding multiple roundtrips in the application and software development process.
GraphQL schema supports basic primitive data types (scalar types) like,
Int – Signed 32‐bit integer
Float – signed double-precision floating-point value
String – Character sequence
Boolean – True or False
ID – ID is a unique identifier in GraphQL.
In addition to these basic types, we can also create and return objects with their own complex properties/behavior in GraphQL.

Here is a type called Ship, which is a complex object with its own characteristic. It contains an ID, name, and Country of type String, builtYear of type Int, and length of type Float.
GraphQL also supports enum types. Enums are special scalar types that are restricted to a particular set of allowed values. For example, we can define an enum called shipType with five values, Cargo, Passenger, Fishing, Military and Tanker.

The shipType is allowed to have any of these five values.
GraphQL Schema can contain query and mutation types. The query represents what the client is asking for, and the mutation is when the client is to add or delete data from the API. This acts as an entry point into the schema. Query and mutation types are treated the same as any other GraphQL object type.
Queries and mutations are the two integral concepts of GraphQL. A graphQL query is used to read data while mutation is used to change/modify data. A GraphQL query essentially deals with asking for specific fields on the object. GraphQL schema is self-documenting and does not need technical documentation efforts. Once the schema is ready, the documentation is generated from the schema.
Example Request:

Example Response :

In GraphQL, we can pass individual arguments to the fields we are querying for. Every field and nested objects can get its own arguments so that a specific query can be asked. It gets rid of any multiple API fetches. So using arguments, we can combine API fetches and have one GraphQL query to fetch the data.
Example : Request

Example : Response

Within the GraphQL query, if you wanted to query for the same field, but with different arguments, it’s not possible. To do that we use aliases. With aliases, we can rename the result of a field.
Fragments are GraphQL’s reusable units that are like functions in a programming language. It lets us build sets of fields and then we can include them in multiple queries, this way the query looks clean and readable.
Variables are used to write dynamic GraphQL queries. Arguments can be dynamic with the use of variables.
Mutations are used to make changes to the data. With GraphQL mutations, we can create, update, or delete the data. GraphQL assumes that there are side effects after mutations and changes the dataset after every mutation. Queries are executed in parallel and mutation fields run in series.
GraphQL takes a declarative data fetching approach. Multiple roundtrips to fetch the data can be avoided with GraphQL. Instead, queries can be grouped together to ask for exactly what you want in one go. Over fetching and under fetching of data can be avoided by using GraphQL. GraphQL is strongly typed. The code that is written with a strongly typed schema is predictable. Predictable code is clean and maintainable. It results in earlier detection of errors. Also, there is no versioning for APIs. Adding new fields will not affect the current clients querying the APIs. GraphQL only returns the data that is requested. So adding new fields and types to the API will not result in breaking changes. With inbuilt self-documentation in the schema, time spends on documentation can be saved.
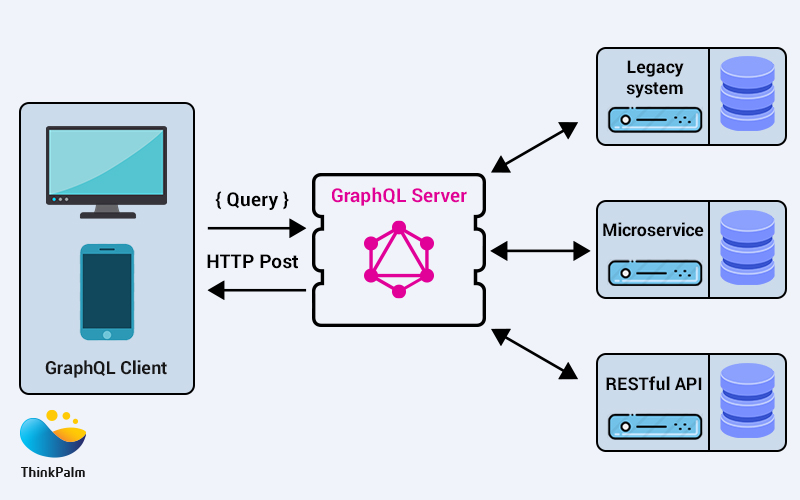
GraphQL Client handles sending requests or queries to the server and receiving the response in the form of a JSON from the server. It also integrates with front-end view components and is responsible for any updates to the UI after it receives a response from the server. GraphQL is entirely based on the schema and the schema essentially acts as a contract between the client and the server. This means the GraphQL Clients can validate and even optimize queries that the client wants to send at build time. It can also help catch errors at an early stage. Apollo and Relay are two frequently used GraphQL clients.
GraphQL Server takes care of the creation of the API and handling the query from the client and sends the appropriate response back. The GraphQL server is where the backend developer will design and create the GraphQL schema, API, and resolver functions. A resolver function resolves a value for a type or field in the GraphQL schema. It can return objects or scalars. Some of the popular GraphQL Server libraries are Apollo Server, Express GraphQL, GraphQL Yoga etc.
Should we make a switch from REST to GraphQL? REST works fine for normal applications, but as the application scales, the drawbacks of REST will become more evident. GraphQL offers more flexibility and better performance with its queries, schemas, and resolvers. GraphQL can increase productivity as frontend and backend teams will be able to work independently. GraphQL APIs need to be tested only when there is a modification to the schema or if there is a new schema. This means reduced cost in testing. For simple APIs with few entities and relationships, GraphQL might be overkill and REST is enough for such applications. But as data gets more complex, GraphQL becomes advantageous. If the application involves a number of microservices and a lot of communication and traffic, then it is better to opt for GraphQL.
If you’re wondering whether an open-source remote procedure call, GRPC will replace REST? Then read our blog to know more.
Lijo M Loyid is a passionate software developer who loves learning and working with new technologies. While not working, he is can be seen watching movies, reading or travelling.