An Introduction To Snowflake Data Warehouse
Industry Updates
 Sumanjali Laddigam
September 7, 2020
Sumanjali Laddigam
September 7, 2020


 Sumanjali Laddigam
September 7, 2020
Sumanjali Laddigam
September 7, 2020

Snowflake is an analytic data warehouse that is provided as Software-as-a-Service (SaaS). It implements a knowledge warehouse that’s faster, easier to use, and much more flexible than traditional data warehouse offerings.
Snowflake’s data warehouse isn’t built on an existing database or “big data” software platform like Hadoop but uses a replacement SQL database engine with a singular architecture designed for the cloud. It uses virtual compute instances for its computing needs and storage service for persistent storage of data. Snowflake can’t be run on private cloud infrastructures (on-premises or hosted). Unlike ELT in the data warehouse, Snowflake cannot join data from different tables and databases, it is also not a packaged software offering that can be installed by a user. (To get more insight into the difference; read Data Lake vs Data Warehouse)
More specifically :
All components of Snowflake’s service (other than an optional command-line client) are run on a public cloud infrastructure.
Snowflake’s architecture is a hybrid of traditional shared-disk database architectures and shared-nothing database architectures. The architecture uses a central data repository for persisted data that is accessible from all compute nodes within the data warehouse. But almost like shared-nothing architectures, Snowflake processes queries using MPP (massively parallel processing) compute clusters where each node within the cluster stores some of the whole data set locally.
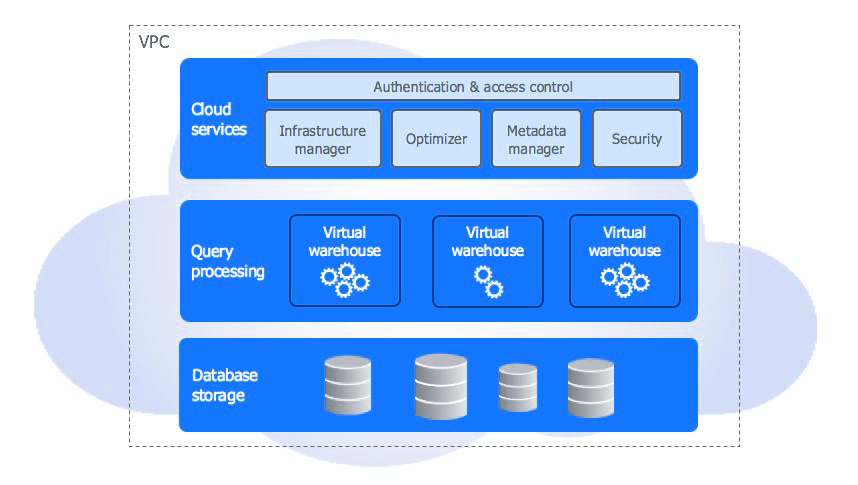
When data is loaded into Snowflake, it reorganizes that data into its internal optimized, compressed, columnar format. Snowflake stores this optimized data in cloud storage.
Query execution is performed in the processing layer. It processes queries using “virtual warehouses”. Each virtual warehouse is an MPP compute cluster composed of multiple compute nodes allocated by Snowflake from a cloud provider.
The cloud services layer may be a collection of services that coordinate activities across Snowflake. These services tie together all of the various components of Snowflake so as to process user requests, from login to question dispatch.
Snowflake supports multiple ways of connecting to the service:
Snowflake Warehouse is a single integrated system with fully independent scaling for compute, storage, and services.
Snowflake is recognized for an interface that’s simple to use and completely intuitive.
No need to worry about configuration, software updates, failures, or scaling your infrastructure as your datasets and number of users grow. Snowflake supports modern features like auto-scaling warehouse size, auto suspends, big data workloads, and data sharing.
Querying data against large datasets is possible using a wide variety of BI tools like Tableau, Looker, Mode Analytics, Chartio, Qlikview, and Power BI.
Pricing is based on the quantity of knowledge you require and the computing hours you employ.
You don’t need to worry about managing, scaling multi-cluster systems, or tuning clusters to urge fast performance. For example, Snowflake includes automatic query optimization.
Snowflake, combined with a knowledge lake, offers unparalleled flexibility and value.
Snowflake, combined with data lake, ensures your data is highly available and durable on Amazon S3 (or Azure).
You have full control over who has access to the data stored in their system. They make it easy to maintain strong security with access management controls, plus data is encrypted at rest and in transit.
Snowflake is a true data platform-as-a-service, it handles infrastructure optimization, data protection, and availability automatically, therefore businesses can focus on using data and not managing it.
Sumanjali Laddigam works at ThinkPalm Technologies as a software engineer. She is passionate about angular & .net programming.